
How to crawl to millions of Wikipedia pages
Wikipedia is a great resource for content – it has millions of content pages, and they are all free for you to use. Crawling to Wikipedia can be useful for SEO and for improving the diversity of content in your blog or website. In this blog I will explain how you could fetch Wikipedia pages summary for any category of pages you want.
Why to scrape the page summary, and not the whole page?
You may want to scrape the page summary only, since it is short enough to be stored but long enough for SEO purposes, and also it could be represented as a plain text only: the full Wikipedia title page is usually complicated, includes footnotes and links – so may be a bit complicated to represent (unless you scrape it as HTML and store in in full). You could however use the following idea to scrape everything, if you really insist so.
The process for scraping all pages of a category
The scraping process I suggest is based on three stages:
1. Search for categories in your niche / interest
You can use the Wikipedia Export Pages function to firstly search for all categories in your niche. This function is accessible at https://en.wikipedia.org/wiki/Special:Export
Enter the special export function and search for your keyword. In this example, I searched for “science”. The search result got us lots of title pages, and also categories pages:
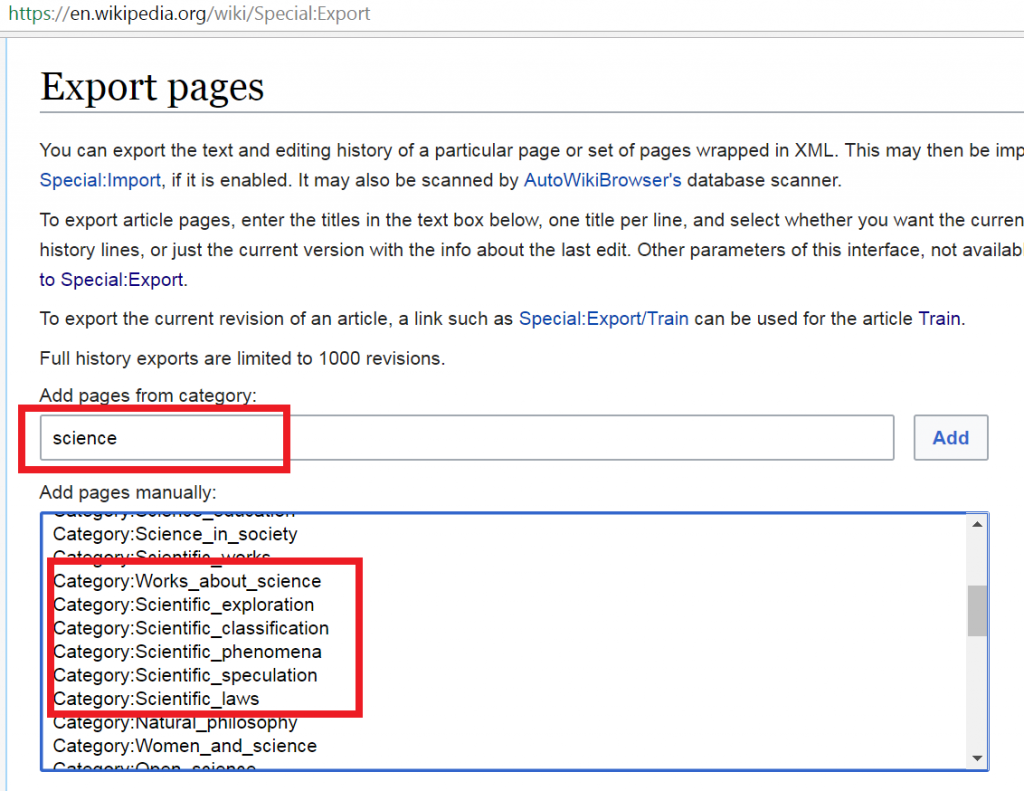
2. Use the Wikipedia API to fetch the list of all pages in your target categories
Once you got a category name that you are after, you can use the Wikipedia API to get all the names of all the pages in that category. In this example, I get all the Wikipedia pages under category:physics by calling this URL:
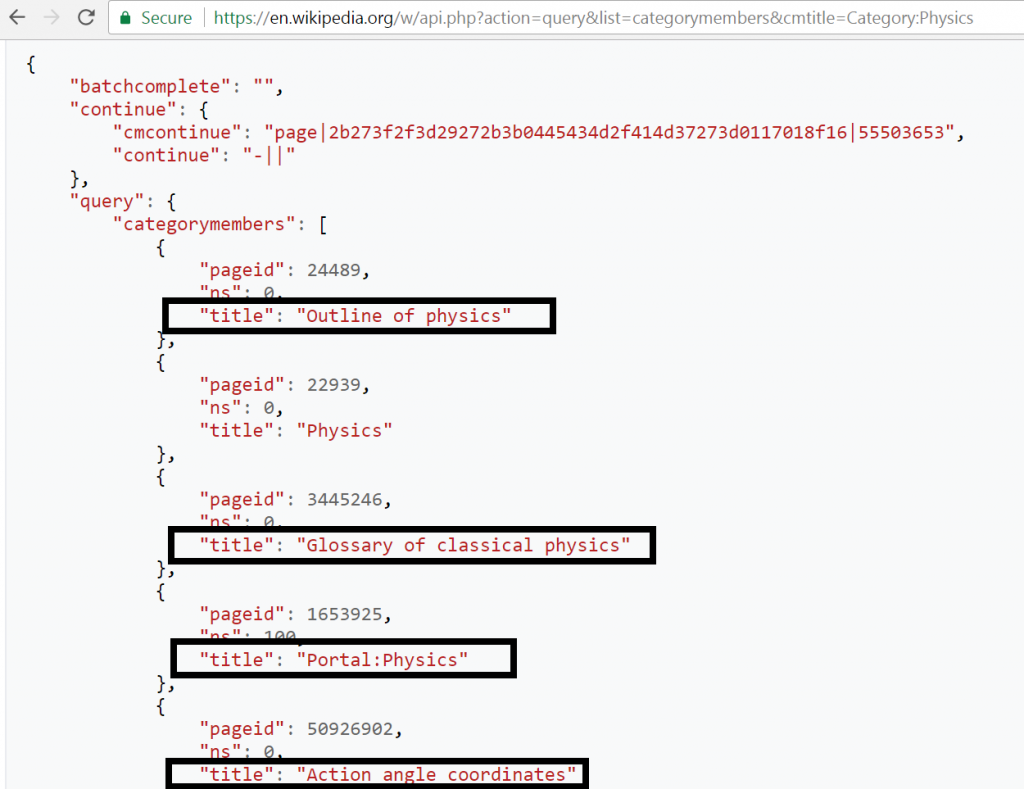
https://en.wikipedia.org/w/api.php?action=query&list=categorymembers&cmtitle=Category:Physics&format=json
The result would look like the following, as you can see, we got all the pages titles and IDs (please note that I cut the output so I present just a portion of it):
3. Use the Wikipedia API to download the summaries of all the pages in your list
Now you could use an automatic process to crawl to each of those title pages, by calling the following API URL, in this case, the one about Physics:
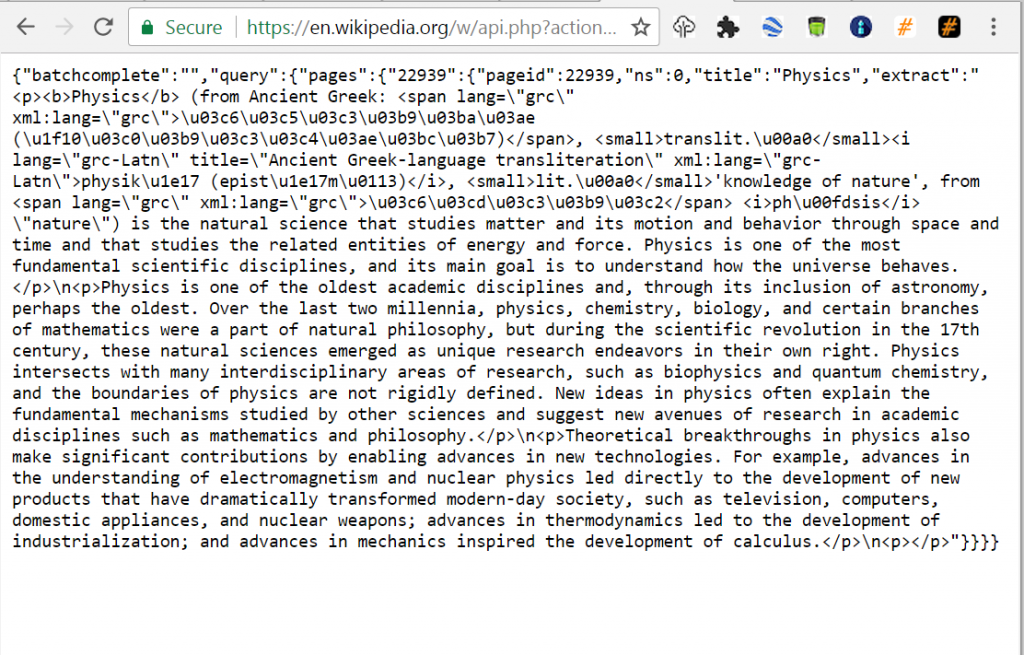
https://en.wikipedia.org/w/api.php?action=query&prop=extracts&format=json&exintro=&titles=Physics
The result is the page summary, which you may want to store in a database:
How a complete PHP scraper code would look like
The following is a script I wrote, that is doing the whole process. I hope you will find it useful, and if questions, please comment below. I hope you enjoy it 🙂


