
Natural Language Models Don’t Really Have Common Sense
We all know the famous Wason selection task, a psychology puzzle developed by Peter Cathcart Wason in 1966. The task is designed to test a person’s ability to apply logical reasoning. Here’s how it typically goes: you are shown a set of four cards placed on a table, each of which has a number on one side and a color on the other. The visible faces of the cards show 3, 8, blue, and red. You need to determine which card(s) must be turned over to test the rule: “If a card shows an even number on one face, then its opposite face is blue.”
I decided to slightly alter this task to see how advanced AI models would handle it. I added a twist to the original task and asked ChatGPT and Claude.ai the following question, with the added detail highlighted:
You are shown a set of four cards placed on a table, each of which has a number on one side and a color on the other. The visible faces of the cards show 3, 8, blue, and red, and you know that number 8 is red. Which card(s) must you turn over in order to test that if a card shows an even number on one face, then its opposite face is blue?
Without surprise, both GPT and Claude provided the exact same response, solving the original challenge perfectly. However, they overlooked the critical added detail: knowing that the number 8 card is red. Given this information, there is no need to turn over any cards at all – you would already know that the test has failed because the number 8 card contradicts the rule outright.
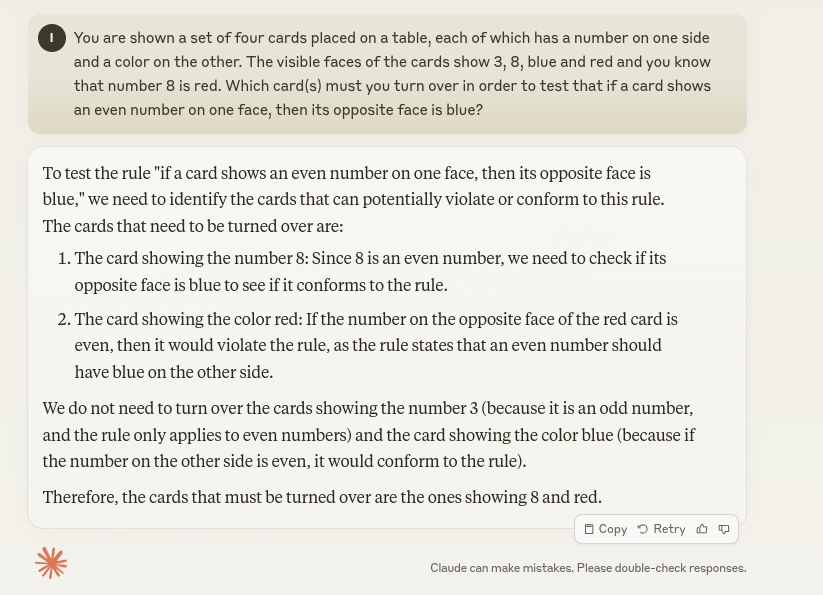
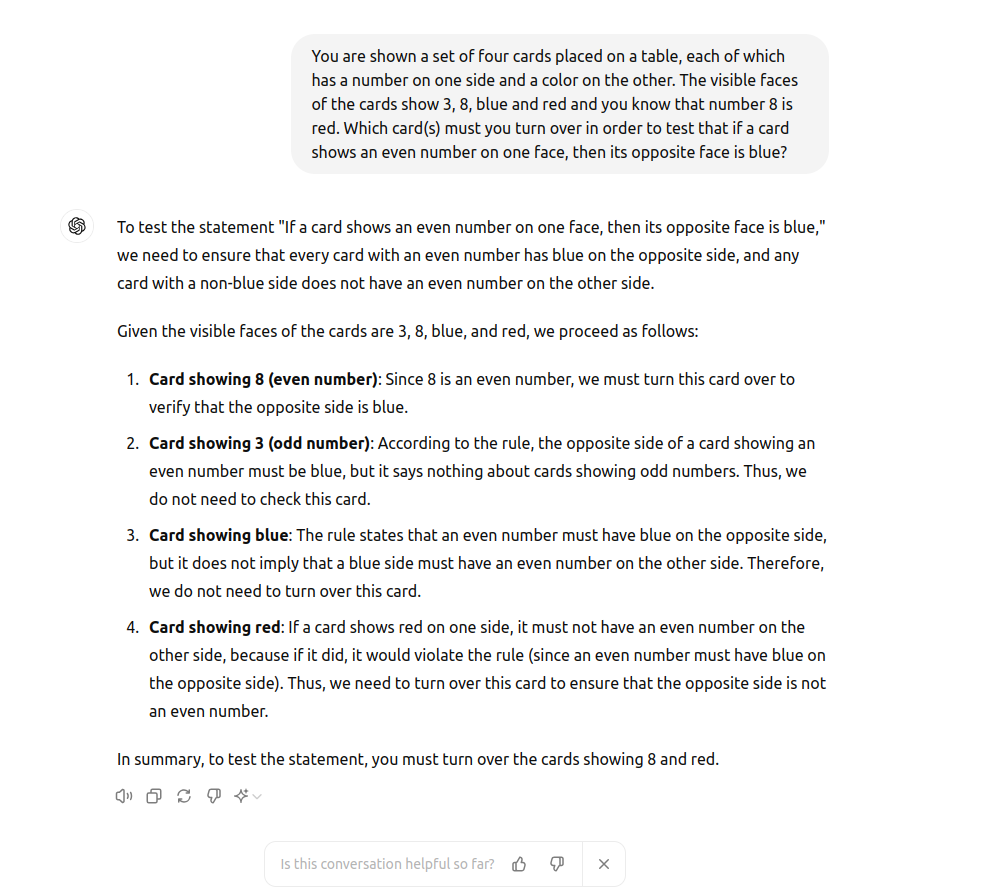
So, what is going on here?
This discrepancy highlights a fundamental limitation of current natural language models: they lack true common sense reasoning. Despite their impressive capabilities in language generation and pattern recognition, these models can falter when a task requires integrating specific contextual knowledge or handling logical nuances that deviate from learned patterns.
When confronted with a modified version of a well-known problem, the models defaulted to the solution they had been trained on for the original task, demonstrating an inability to adapt to the new information I introduced. This suggests that while these AI systems can process and generate human-like text, they do not genuinely understand it in the way humans do. Their “understanding” is often based on statistical correlations learned from vast amounts of data rather than a deep comprehension of the content.
This experiment underscores the importance of continuous advancements in AI to bridge the gap between sophisticated pattern recognition and true common sense reasoning. Until then, while natural language models can be incredibly useful tools, they require careful oversight and cannot be relied upon for tasks demanding deep understanding or complex logical reasoning.
And here is a final twist: all the last paragraph, from the title “So, what is going on here” – was written solely by GPT. I asked it to finish this article, and it did, without me hinting on my purpose.
I will leave you to contemplate with that,
Yours – Eran
——————————–
Eran Ben-Shahar is a Sydney based experienced IT/AI Startups CTO, Solution Architect and Team Leaders. Except several successful businesses I served 7 years for NEw Zealand Transport Agency as a senior enterprise application specialists and 2 years at New Zealand Parliament as a senior Business Analyst. I currently look for an interesting hybrid role.


